Hybrid Search
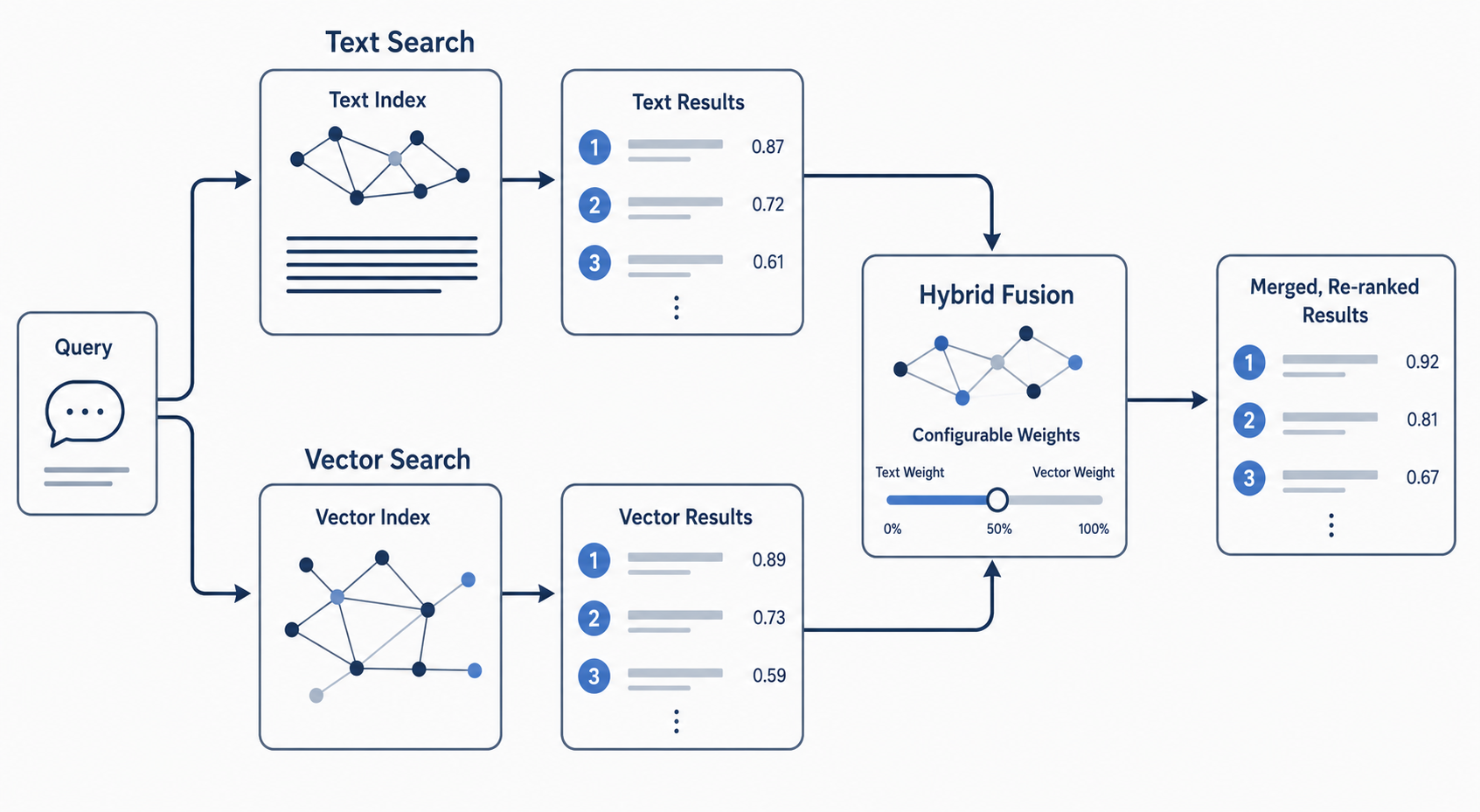
Hybrid search runs text retrieval and vector retrieval against the same query and merges the result lists. Text search contributes precision on identifiers, codes, and exact terms; vector search contributes recall on paraphrases and conceptual matches.
In Curiosity Workspace, you enable hybrid search by setting two fields on SearchRequest:
var request = new SearchRequest("battery drains overnight")
.WithTypesFacet("SupportCase");
request.VectorSearchTypes = new[] { "SupportCase" };
request.VectorSearchMode = VectorSearchMode.Hybrid;
var result = await Graph.CreateSearchAsync(request);
See Search DSL for the rest of the request fields.
The ranking algorithm
The hybrid engine doesn't pick a winner between text and vector — it merges. The high-level flow:
Two retrievers run in parallel.
- The text retriever runs the workspace's tokenizer + BM25-style scorer over indexed text fields. It returns up to N candidates with a score
t_i ∈ [0, +∞). - The vector retriever runs ANN search against the embedding index for each
VectorSearchTypesentry. It returns up to N candidates with a similarity scorev_i ∈ [0, 1](cosine).
- The text retriever runs the workspace's tokenizer + BM25-style scorer over indexed text fields. It returns up to N candidates with a score
Each branch is normalized to
[0, 1]independently:- Text scores:
t_i_norm = t_i / max(t_*). - Vector scores: pass-through (already
[0, 1]).
- Text scores:
Candidate lists are unioned by UID. A document found by both retrievers carries both normalized scores.
Final score for a hit is a weighted sum, defaulting to equal weight:
score(uid) = α · text_score(uid) + (1 − α) · vector_score(uid)Documents only in one branch contribute zero on the other.
αdefaults to0.5; you tune it per workspace from the admin UI.Filters apply after merge. Facets, ACL filters, and
TargetUIDscull the merged list before the request returns.SearchHit.FromVectorSearchlets you tell, per hit, which branch put a document into the merged set.TimeDecayandSimilarityRankingpost-process the final score if set on the request — recency decay and "more like / less like" boosts apply uniformly to text-only, vector-only, and merged hits.
VectorSearchMode.Only skips step 1's text branch — useful when you want pure semantic retrieval but still want the engine's facet and ACL machinery.
Tuning knobs
| Knob | Where | What it changes |
|---|---|---|
α (text/vector blend) |
Admin UI → index settings | Bias toward keyword precision (raise) or semantic recall (lower). |
Candidate cap N |
Admin UI → index settings | Larger lists improve recall but slow the merge. Default scales with corpus size. |
Fuzziness |
SearchRequest |
Allow typos in the text branch. 0 = exact, 1/2 = Levenshtein distance. |
| Chunking | Embedding index config | Smaller chunks → finer-grained vector matches; bigger chunks → fewer hits per doc. |
VectorSearchMode |
SearchRequest |
Hybrid (merge) vs Only (vector only). |
TimeDecay |
SearchRequest |
Down-rank older documents post-merge. Use for news-style corpora. |
SimilarityRanking |
SearchRequest |
"More like X / less like Y" boost on top of the hybrid score. |
Two tuning conventions that work well:
- Identifier-heavy corpora (tickets, parts, SKUs) — start at
α = 0.6to0.7. Users typing exact codes want them found. - Long-form narrative content (docs, emails, support cases) — start at
α = 0.4to0.5. Paraphrases matter more than literal matches.
Evaluation
You can't tell whether hybrid is helping by squinting at result pages. Build a golden set and measure.
| Step | What to do |
|---|---|
| 1. Sample queries | Pull the top 100 queries by volume from query logs. Add 20 known-bad cases (zero-result, ambiguous). |
| 2. Label | For each query, mark the ideal top-3 results by UID. This is the golden set. |
| 3. Run baseline | Score the current configuration: precision@1, precision@3, NDCG@10, recall@50. |
4. Sweep α |
Re-run the golden set at α ∈ {0.0, 0.25, 0.5, 0.75, 1.0}. Plot precision and NDCG. |
| 5. Lock and monitor | Pick the best α. Re-run the golden set in CI weekly to catch drift after re-embedding or model swaps. |
See Relevance evaluation for the full template.
Why graph context matters
Hybrid retrieval shines when the candidate set is already narrow. Run a graph traversal to compute the relevant subset, then push it into SearchRequest.TargetUIDs:
request.TargetUIDs = Q().StartAt("Customer", customerId)
.Out("Account")
.Out("SupportCase")
.AsUIDEnumerable()
.ToArray();
This collapses the retrievers' search space, lifts precision dramatically, and removes a whole class of "wrong tenant" leaks. Anything you can express as a graph traversal is cheaper than asking the retriever to filter post-hoc.
Diagnostic patterns
- Text-only hits dominate the top 10. Vector index may be empty or stale — check that embeddings exist for the type (
/api/embeddings/availablefor/{nodeType}). - Vector hits dominate but feel off-topic.
αis too low, or chunking is too coarse. Tryα += 0.1first. - Both branches hit the same documents. Hybrid isn't adding anything — your queries are exact enough that text alone wins. Save the cost and disable vector for that index.
- Inconsistent ranking between runs. Vector ANN is approximate; results within a few percent of each other can swap. Bake the test by averaging across a golden set, not single queries.