Vector Search
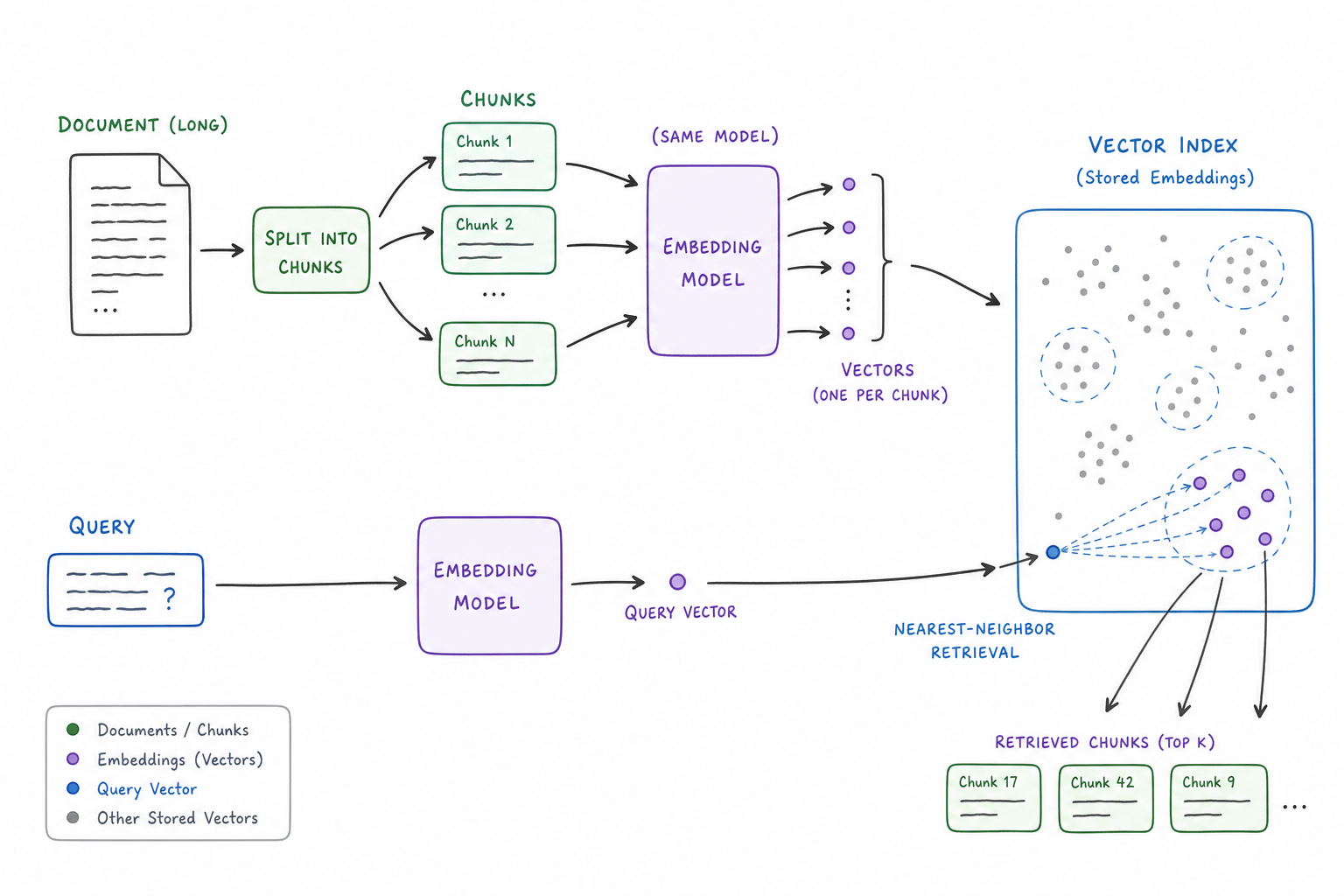
Vector search (also called semantic search) retrieves results by meaning rather than by exact keyword match. Curiosity Workspace produces an embedding for each indexed text chunk and stores it in a vector index; queries are matched against that index using approximate nearest-neighbor search.
For exact-keyword retrieval, use Text Search. For most production search experiences, use Hybrid Search, which combines both.
When to use vector search
Vector search is the right tool when:
- users describe what they want in their own words ("the slow customer issue") rather than with known keywords;
- the indexed text is long and descriptive (notes, transcripts, knowledge-base articles);
- you need "similar items" UX (similar tickets, related documents);
- you operate across multiple languages with paraphrased intent.
It's a poor fit for:
- short identifier lookups (
T-9182, SKUs, serial numbers) — text search wins on precision and cost; - fields where exact case/spelling matters — vector search will return "close enough" matches that are wrong;
- corpora too small to benefit (< 1 000 documents — text search is usually sufficient).

Core concepts
| Concept | What it is |
|---|---|
| Embedding model | A model that maps text → a dense vector. The model determines vector dimension and behavior across languages. |
| Vector index | An approximate-nearest-neighbor index over those vectors. |
| Chunk | A piece of a long field that is embedded as a unit. |
| Similarity score | How close two vectors are. Higher = more similar. The workspace normalizes scores to roughly [0, 1]. |
| Top-k | How many nearest neighbors the search returns. |
| Threshold | A minimum similarity below which results are dropped. |
What to embed
Good candidates:
- Descriptions and bodies of tickets, articles, cases.
- Conversations and transcripts (meeting notes, support threads, calls).
- Knowledge-base articles and product documentation.
- Long summaries that capture the gist of an entity.
Poor candidates:
- Short identifiers (IDs, SKUs, codes) — text retrieval handles these better and faster.
- Booleans, enums, dates — these belong in property facets.
- Highly repetitive boilerplate — wastes index space without improving recall.
A good default: embed exactly the fields a user would describe in plain English. Everything else lives in text search and facets.
Chunking strategy
If a field can be longer than the embedding model's effective context (typically a few hundred to a few thousand tokens), enable chunking. Without chunking, the model either truncates or averages, and retrieval quality drops.
| Decision | Recommendation |
|---|---|
| Chunk size | 200–800 tokens for most domains. Start at 512. |
| Chunk overlap | 10–20% of chunk size (e.g., 64 tokens for 512-size chunks) to avoid splitting a sentence across chunks. |
| Chunk boundaries | Prefer paragraph boundaries; fall back to sentence; fall back to fixed token windows. |
| Per-chunk metadata | The workspace stores the parent UID, so retrieval returns the parent node and a snippet pointer. |
Tradeoffs:
- Too small: many chunks per document → high index size and embedding cost; retrieval surfaces fragments without context.
- Too large: few chunks → cheaper but each chunk is a coarser semantic unit, hurting precision.
You can tune chunking per field — short summaries don't need chunks; long bodies do.
Embedding model selection
The choice depends on your data, your latency target, and your data-residency posture. See the provider matrix in LLM Configuration.
| Goal | Pick |
|---|---|
| Highest retrieval quality | A frontier hosted embedding model (text-embedding-3-large, voyage-3-large, etc.) |
| Predictable cost at scale | A mid-tier hosted model (text-embedding-3-small) |
| Strict data residency | A local model — built-in MiniLM/FastText, or a server you control |
| Multi-language corpus | A multilingual model — most modern hosted models cover 50+ languages; some local models are English-only |
Once you switch models, you must re-embed the corpus: vectors from different models are not comparable. See Reindexing and re-embedding.
Configuring vector search
Under Settings → Search → Indexes:
- For the node types you want findable, mark the long-text fields as vector-indexed.
- Enable chunking for those fields.
- Pick a chunk size and overlap.
- Save — the workspace begins backfilling embeddings in the background.
- Watch progress under Settings → Tasks.
You can also drive this from a connector: set RegisterEmbeddingFields() for the fields you want embedded when you call CreateNodeSchemaAsync<T>().
Top-k and thresholds
Take(k)sets the number of nearest neighbors to return. Most chat/RAG flows usek = 8. Most "similar items" UIs usek = 5–10.- Threshold drops candidates below a minimum similarity. Without one, the search always returns
kresults, even when none are actually similar. Start at0.55–0.65and tune.
return (await Q().StartAtSimilarTextAsync("Apple screen issue",
nodeTypes: new[] { "Ticket" },
count: 10,
applyCutoff: true))
.EmitWithScores();
Context-constrained vector search
The most powerful pattern in Curiosity: combine semantic similarity with graph constraints. The vector search runs only within a target set computed by a graph traversal.
// Similar tickets, but only those for products from a specific manufacturer
class SimilarRequest { public string Query { get; set; } public string Manufacturer { get; set; } }
var req = Body.FromJson<SimilarRequest>();
return (await Q().StartAtSimilarTextAsync(req.Query,
nodeTypes: new[] { "Ticket" },
count: 100))
.IsRelatedTo(Node.GetUID("Manufacturer", req.Manufacturer))
.EmitWithScores();
This is fast (the candidate set is bounded by the graph filter) and precise (semantic neighbors that aren't related to the manufacturer never make it to ranking).
Permission-aware vector search
Use the user-context variant for any user-facing surface:
var search = SearchRequest.For(req.Query);
search.BeforeTypesFacet = new([] { "Ticket" });
// hybrid: text + vector both filtered by user permissions
var query = await Graph.CreateSearchAsUserAsync(search, CurrentUser, CancellationToken);
return query.Take(10).Emit("N");
The ACL filter is applied to the candidate set before ranking, so the user never sees nodes they can't access.
Multilingual behavior
A multilingual embedding model produces vectors that compare across languages: a French query can match an English document if their meaning matches. Behavior to verify when you turn this on:
- The model actually supports your languages (consult the model docs).
- Stop-word and stemming behavior aligns with your dominant language.
- Test a small set of cross-language queries against known matches.
If your content is split per language and users don't expect cross-language results, configure separate fields per language and turn off cross-language retrieval.
Failure modes
| Symptom | Likely cause |
|---|---|
| Vector search returns nothing | Embedding provider unreachable, or the embeddings haven't been built yet. Check Settings → AI Settings. |
| Vector search returns irrelevant results | Threshold is too low. Set applyCutoff: true so the index's configured threshold is enforced. |
| Vector search returns the same item across many queries | Chunking is too aggressive — one document dominates. Increase chunk size or trim boilerplate. |
| Quality regressed after a model switch | You're comparing vectors from different models. Re-embed the corpus. |
| Latency p95 spiked | Provider rate-limited, or queue depth grew during a large rebuild. |
Common pitfalls
- Embedding everything: indexes get huge, retrieval gets diluted, costs balloon. Embed user-facing long text only.
- No grounding: passing raw similarity results to an LLM without facets or graph constraints produces hallucination-prone answers.
- No evaluation set: relevance regresses silently after model or chunking changes. Maintain a small set of golden queries.
- Chunks without overlap: a query that lands on a chunk boundary misses the match.
Next steps
- Combine with text retrieval: Hybrid Search.
- Tune cutoffs and chunking systematically: Ranking Tuning.
- Configure the provider: LLM Configuration.
- Embedding concepts and lifecycle: Embeddings.
- Reference: Embeddings API, Search DSL.
Referenced by
- FAQ
- LLM Configuration
- Multimodal Search (OCR & STT)
- Multimodal Search Tutorial
- Semantic Similarity
- AI Models
- Search Model
- Schema Design
- Migration: Elasticsearch + vector DB + LangChain
- Build your first enterprise AI app
- Embeddings
- Embeddings API
- Schema Reference
- Federated Search
- Hybrid Search
- Ranking Tuning
- Text Search
- Technical Support Use-Case