Data Flow
Curiosity Workspace data flow describes how raw source data becomes:
- Structured (schemas, properties, graph edges)
- Findable (text and vector indexes)
- Actionable (endpoints, interfaces, AI workflows)
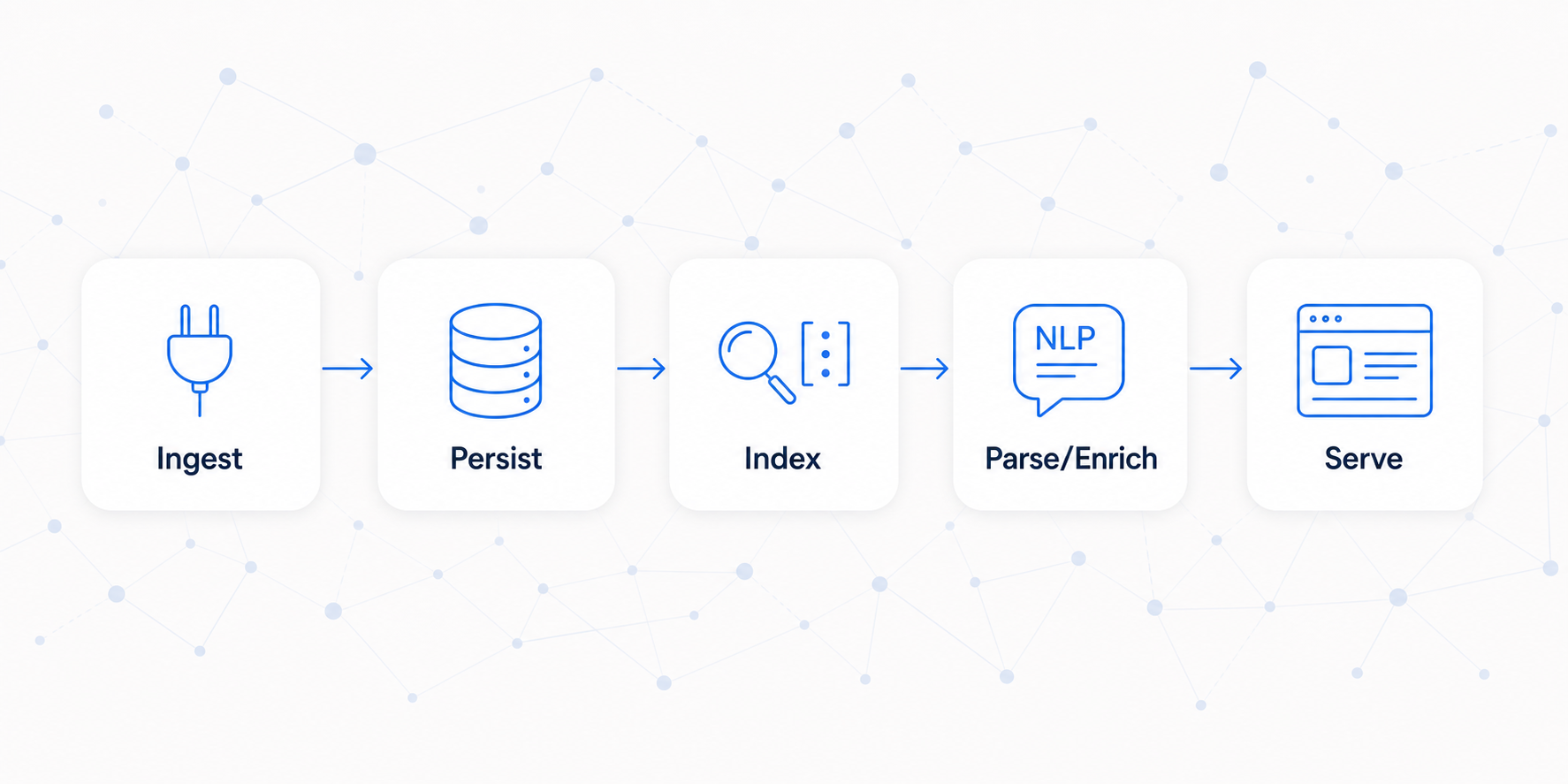
End-to-end pipeline (conceptual)
- Ingest
- A connector/integration reads source records and maps them into node/edge schemas.
- Persist
- Nodes and edges are committed into the workspace graph storage.
- Index
- Selected fields are indexed for text search and/or embedding search.
- Parse / enrich (optional)
- NLP pipelines extract entities/signals from text and can link them into the graph.
- Serve
- UI, APIs, and endpoints read from graph + search to deliver experiences.
Practical breakdown
Ingestion (connectors and pipelines)
- Connectors are best when you need full control over mapping, identifiers, and relationship creation.
- Pipelines/integrations are best when your source is a standard system and configuration is enough.
See Data Integration → Connectors.
Graph modeling (schemas + keys)
Your data model decisions determine everything downstream:
- keys determine deduplication and update behavior
- edges determine navigation and graph-based filtering
- properties determine searchability and faceting
See Data Integration → Schema Design.
Indexing (text + vector)
- Text search is ideal for identifiers, titles, keywords, and exact terms.
- Vector search is ideal for meaning-based retrieval across longer text.
- Hybrid search combines both for strong recall and precision.
See Search.
NLP enrichment (optional)
NLP can add:
- entity extraction (people, products, IDs, concepts)
- entity linking (connect extracted entities to existing nodes)
- derived signals used for filtering or ranking
See NLP → Overview.
AI workflows (optional)
AI features typically rely on:
- grounding from search + graph (to reduce hallucinations)
- custom endpoints to orchestrate retrieval, scoring, and business rules
- interfaces tailored to the workflow (support, investigation, research, etc.)
See AI & LLMs → Overview and APIs & Extensibility.
Observability checkpoints
When something “doesn’t work”, validate in this order:
- Ingestion: are nodes/edges being created? (counts, keys, errors)
- Graph correctness: do expected relationships exist?
- Indexing: are fields indexed? is a rebuild required?
- Parsing: are pipelines applied to the right fields?
- App logic: do endpoints/UI queries match the data model?
Next steps
- Learn the graph mental model: Graph Model
- Learn how search fits the model: Search Model