Architecture
Curiosity Workspace is a single deployable that brings together three layers that usually require separate systems:
- Graph layer — a typed, schema-driven knowledge graph (nodes, edges, properties, traversals).
- Search layer — text, vector, and hybrid retrieval with property and graph-relationship facets.
- AI layer — embeddings, NLP enrichment, LLM orchestration, AI tools, and agents.
The unified runtime is the point: graph relationships improve search filtering, search results ground AI answers, and permissions (ReBAC) are enforced consistently across all three.
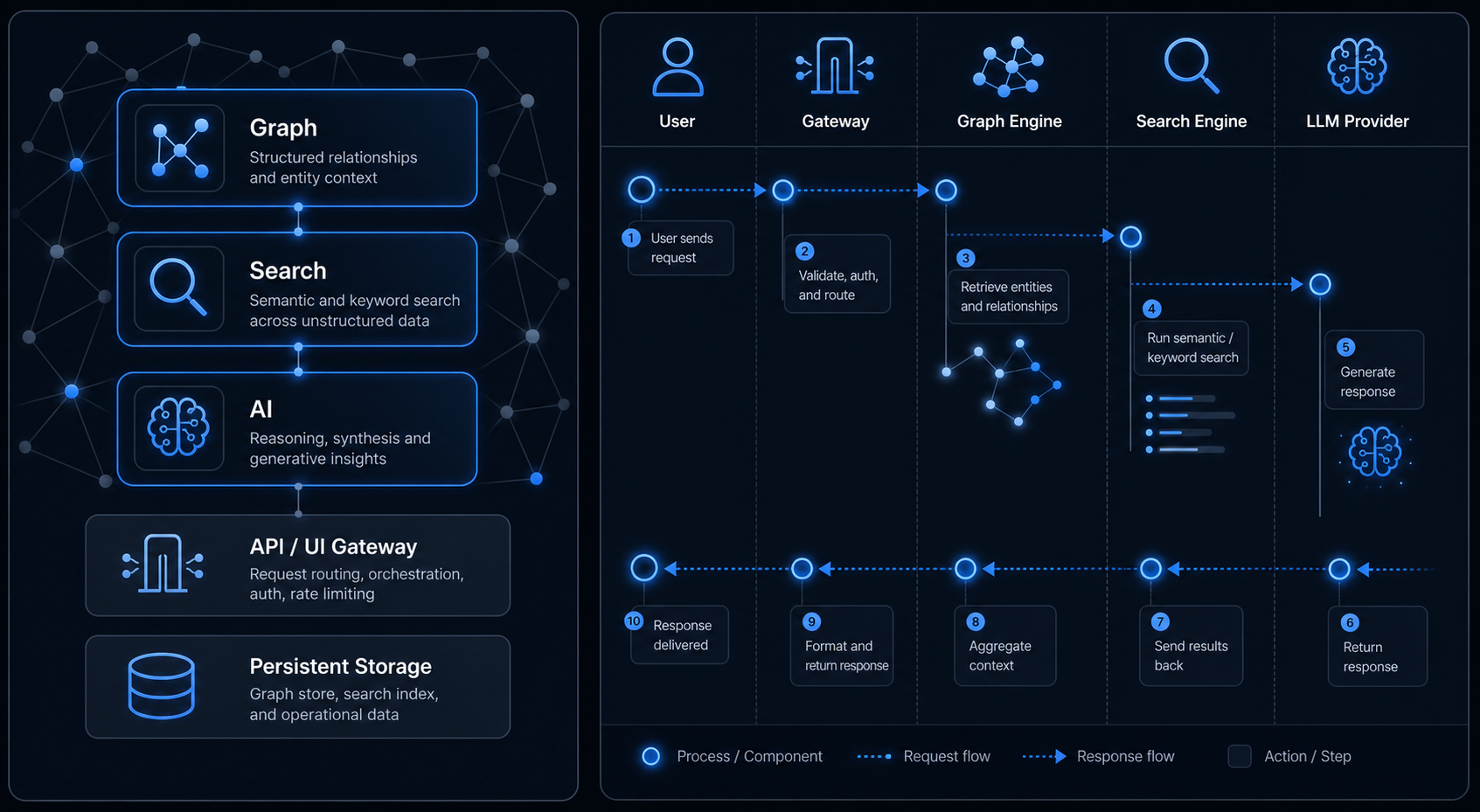
Components
| Component | Purpose |
|---|---|
| API & UI Gateway | Kestrel-hosted HTTP server. Serves the built-in front-end and routes programmatic requests. JWT authentication and ReBAC are enforced here. |
| Graph Engine | In-memory, purpose-built engine for low-latency traversals and high-throughput updates. ACID writes, lock-free reads. |
| Search Engine | Text and vector indexes built from explicit field configuration. ACLs are indexed alongside content and applied at query time. |
| Parsers | Background processes that extract text and metadata from incoming files (OCR, STT, format-specific parsers). Sandboxed via Landlock on Linux. |
| Linkers | Background processes that materialize edges from parsed content (entity linking, deduplication, similarity edges). |
| Custom Endpoints / AI Tools | C# code that runs inside the workspace, with full access to the graph, search, and AI runtime. |
| Scheduled Tasks | Cron-driven background work for ingestion, reindexing, enrichment, and analytics. |
Deployment model
- Single-container delivery (
curiosityai/curiosity). The Workspace is a single Kestrel-hosted process with internal threading rather than a fleet of microservices — components are reached as in-process calls. - Out-of-process sandbox for file parsing only (Landlock on Linux), so a malicious document can't compromise the workspace itself.
- Persistent storage at
MSK_GRAPH_STORAGE. Backing storage is platform-specific (EBS, Azure Disk, Persistent Disk, vSphere, local SSD). - Vertical scale first — the graph engine is memory-resident; more RAM and faster disk are the primary scaling levers. Horizontal scaling (read replicas) is on the roadmap for very-large deployments.
See Storage and indexing for the detailed layout and Scaling for capacity planning.
Request flows
Search and discovery
sequenceDiagram
participant U as User
participant FE as Front-end
participant GW as Gateway
participant S as Search Engine
participant G as Graph Engine
U->>FE: types query
FE->>GW: POST /api/cce/search (Bearer JWT)
GW->>GW: validate JWT, resolve user + teams
GW->>S: SearchRequest + user's ACL filter
S->>S: text + vector retrieval
S->>G: hydrate nodes / neighbors
G-->>S: nodes
S-->>GW: ranked, ACL-filtered results
GW-->>FE: JSON
AI-assisted answer (RAG)
sequenceDiagram
participant U as User
participant Chat as Chat view
participant GW as Gateway
participant Tools as AI tool runtime
participant S as Search Engine
participant LLM as LLM provider
U->>Chat: asks a question
Chat->>GW: chat turn
GW->>Tools: invoke chat with available tools
Tools->>LLM: prompt + tool definitions
LLM-->>Tools: tool call (e.g., FindSimilarTickets)
Tools->>S: CreateSearchAsUserAsync(req, CurrentUser)
S-->>Tools: ACL-filtered nodes
Tools->>Tools: AddSnippet(uid, text) for citations
Tools->>LLM: tool result
LLM-->>Tools: answer with [snippet] refs
Tools-->>GW: answer + tool-call trace
GW-->>Chat: rendered answer with citations
Ingestion
sequenceDiagram
participant C as Connector
participant GW as Gateway
participant G as Graph Engine
participant P as Parsers/Linkers
participant S as Search Engine
C->>GW: API token (ingestion scope)
C->>G: TryAdd(Node), Link(...)
C->>G: CommitPendingAsync()
G->>P: notify new content
P->>G: parsed text + extracted entities
P->>G: add MentionsEntity edges
G->>S: index changed fields (text + vector)
S-->>S: new content searchable
ACID and concurrency
- Writes are ACID: a
CommitPendingAsync()either applies in full or not at all. Two writers committing the same logical entity concurrently get one winner; the other gets acommit_abortederror and can retry. - Reads are lock-free: heavy query traffic and ingestion coexist without blocking each other.
- Index updates are eventually consistent with respect to writes — there's a small window where a freshly committed node is in the graph but not yet in the search index. Application code that requires read-your-writes should query the graph directly, not the search engine, during that window.
Security model (ReBAC)
- Access is determined by paths in the graph: user → team → owns → resource.
- ACLs are ingested by the connector via
RestrictAccessToTeam,RestrictAccessToUser,MarkFileAsPrivate. - At query time, the search engine compiles the user's team memberships into an ACL filter and applies it before ranking.
- The graph engine enforces the same check on direct fetches.
See Access Control Model for the full deep dive and Permission model architecture for the data flow.
Failure modes worth knowing
| Failure | Impact | Mitigation |
|---|---|---|
| LLM provider unreachable | Chat and RAG tools fail; search/graph keep working | Configure a fallback provider; degrade gracefully in tool code |
| Embedding provider unreachable | New nodes don't get vector entries; pure text retrieval still works | Vector queries return text fallbacks; rebuild after recovery |
| Storage full | Writes fail; reads continue from in-memory state until restart | Alert on disk usage > 80% and expand the PVC |
| OOM during embedding rebuild | Container restart loop | Scale up RAM, or stage the rebuild during low traffic |
MSK_GRAPH_MASTER_KEY change |
Encrypted properties unreadable | Treat the key as the most important secret you back up |
Design goals
- Schema-first clarity — you control which types exist and how they relate.
- Configurable retrieval — tune relevance without rewriting your app.
- Safe extensibility — move business logic into versionable endpoints and controlled interfaces.
- Operational control — every deployment can be monitored, secured, and promoted across environments.
Next steps
- Data Flow — how data moves through the system end-to-end.
- Graph Model — schema, keys, edges, properties.
- Search Model — what gets indexed and how it's ranked.
- Permission model architecture — ReBAC ingestion and enforcement.
- Storage and indexing — on-disk layout.
- RAG and agent architecture — the AI runtime in detail.