Vector search
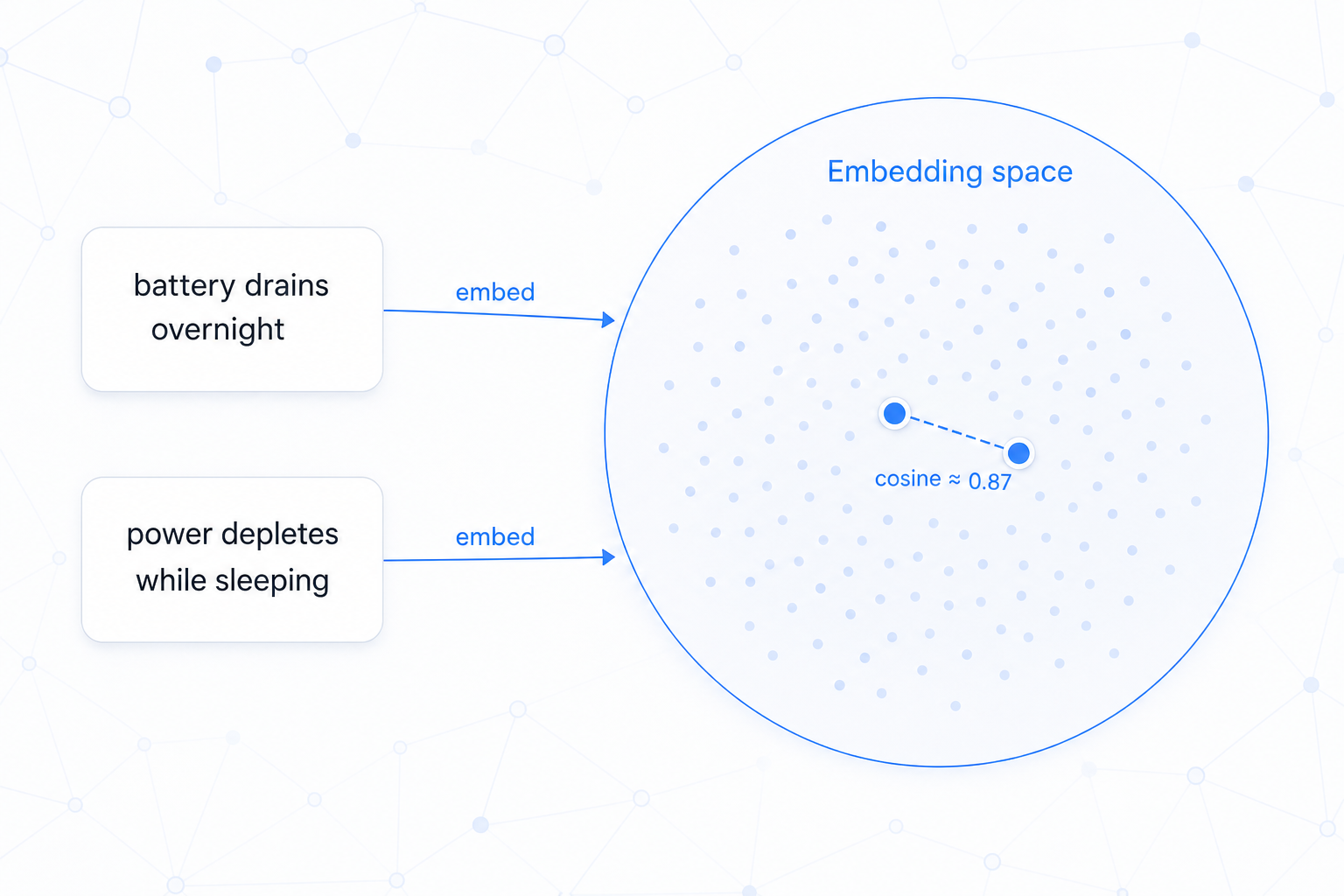
Semantic retrieval using embeddings. Finds conceptually similar content even when no keywords match.
Core concepts:
| Term | What it means |
|---|---|
| Embedding | Dense numeric vector representing the meaning of a text |
| Cosine similarity | Score ∈ [0, 1] — how close two vectors are in meaning |
| Chunk | A segment of a long field, embedded separately |
| Threshold | Minimum similarity to include a result (start at 0.55–0.65) |
| Top-k | Number of nearest neighbours to return (8 for RAG, 5–10 for "similar items") |
Enable in Settings → Search → Indexes: mark a field as vector-indexed, set chunk size and overlap. A background job backfills all existing nodes.
Picking an embedding model:
| Goal | Model |
|---|---|
| Best quality | text-embedding-3-large (OpenAI) |
| Predictable cost | text-embedding-3-small |
| No data egress | Built-in MiniLM or ArcticXS |
| Multilingual | Any modern hosted model |
If you switch embedding models, you must re-embed the entire corpus. Vectors from different models are not comparable.