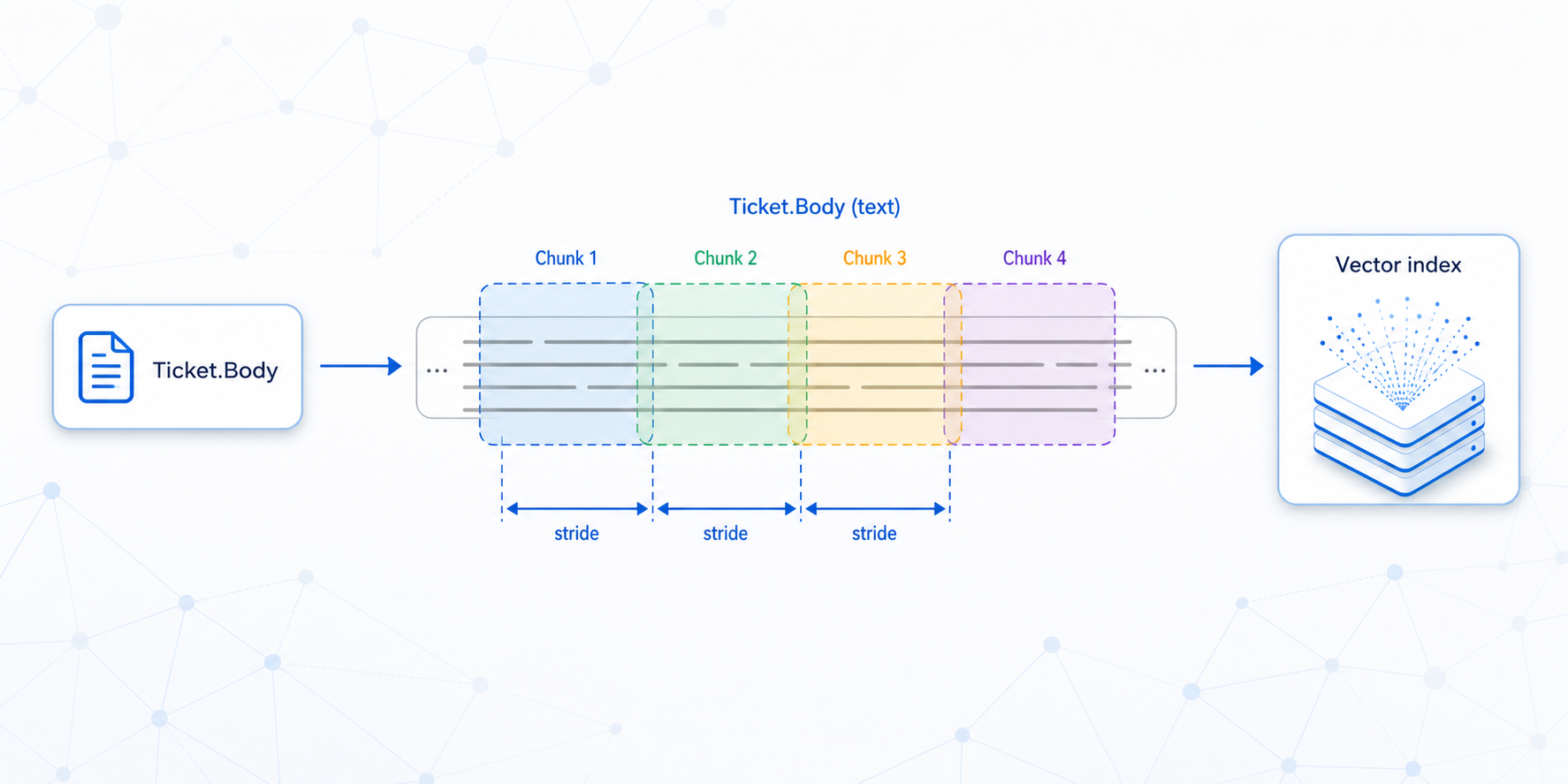
Sentence embeddings
Embeddings are the foundation. Each text field you mark as vector-indexed gets encoded into a dense vector and stored in an approximate nearest-neighbour (ANN) index.
Built-in models:
| Model | Max tokens | Best for |
|---|---|---|
| MiniLM | 256 | Fast, low-RAM, good for short fields |
| ArcticXS | 512 | Higher recall, default for new indexes |
| External (OpenAI-compatible) | 4096 | Highest quality, text leaves your network |
Register a vector index in code:
await Graph.Indexes.AddSentenceEmbeddingsIndexAsync(
nodeType: "Ticket",
fieldName: "Body",
model: SentenceEmbeddingsModel.ArcticXS);
Or enable it in Settings → Search → Indexes without writing code.
Find similar nodes by text:
var similar = await Q()
.StartAtSimilarTextAsync("battery drain overnight", count: 10, nodeTypes: ["Ticket"]);
Find neighbours of a known node:
var similar = Q().StartAt(seedUID).Similar(indexType, indexUID, count: 10);