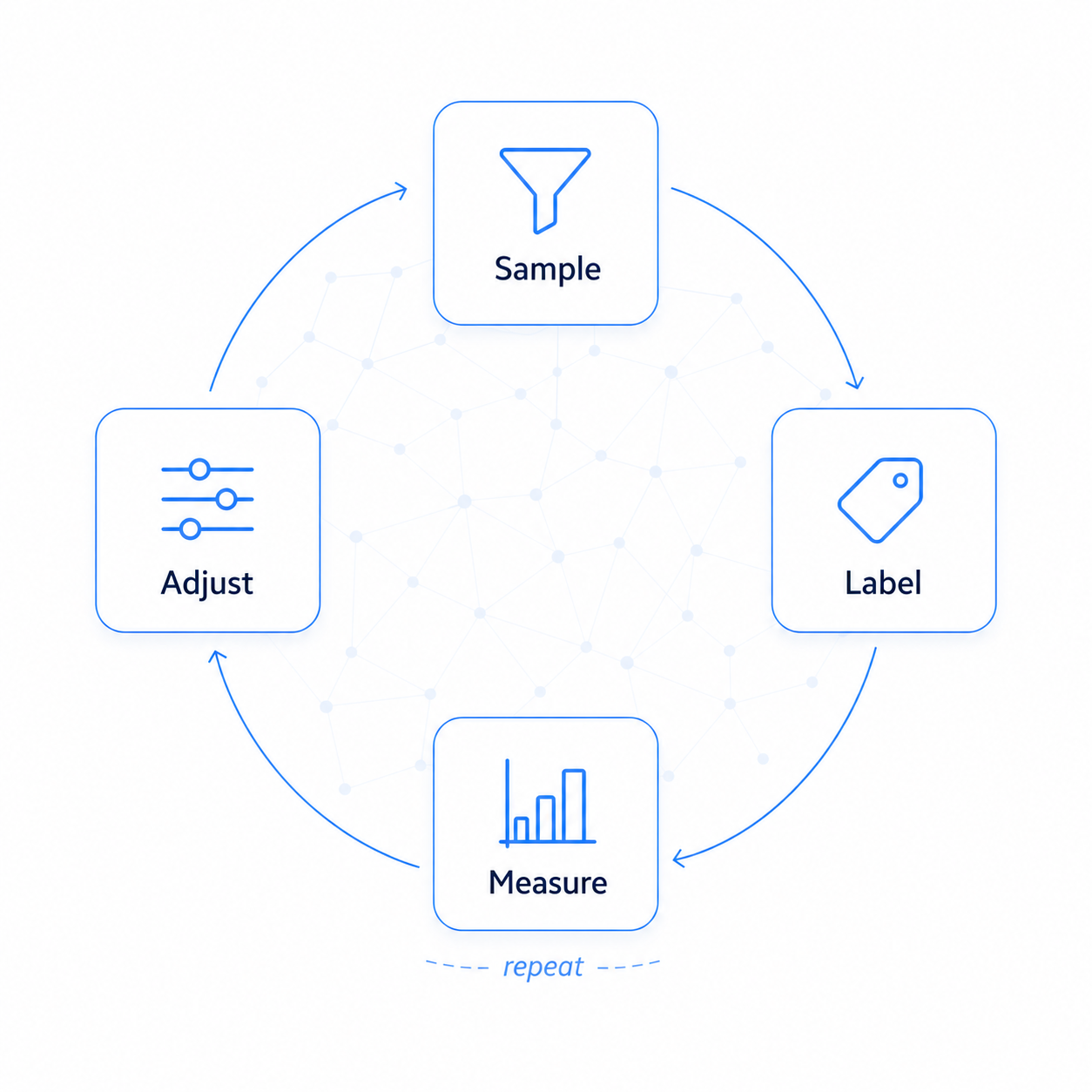
Tuning and review
Extraction quality degrades silently if you don't measure it. Build a review loop before promoting pipelines to production.
The review workflow:
- Sample 100–200 representative documents
- Run extraction in shadow mode (results logged, not committed)
- Hand-label a sample: True Positive / False Positive / False Negative
- Compute precision (of what we extracted, how much was correct) and recall (of what exists, how much did we find)
- Adjust and re-run
Tuning moves:
| Problem | Fix |
|---|---|
| Too many false positives | Raise min_confidence; add exclusions |
| Missing known entities | Add aliases; lower threshold for that entry |
| New entity types not covered | Add dictionary entries or a pattern spotter |
Triggering a reparse:
After changing a pipeline, trigger a reparse in Settings → Schema → [type] → Reparse this data. This re-runs the pipeline over all existing nodes for that type and field.