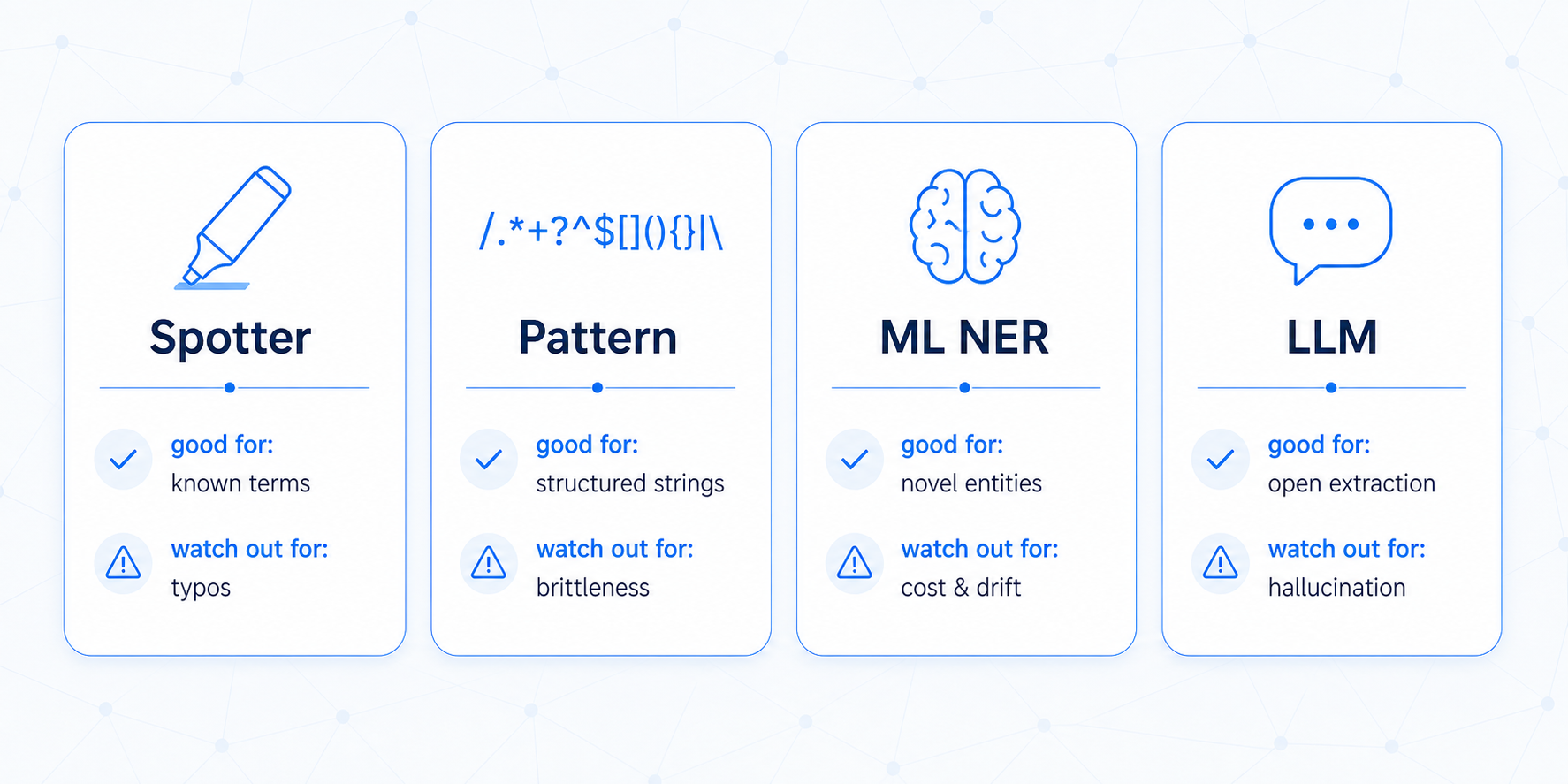
Extraction models
Four ways to find entities in text. Pick based on your vocabulary and tolerance for false positives.
| Model | How it works | Good for | Watch out for |
|---|---|---|---|
| Dictionary spotter | Matches a fixed vocabulary with aliases | Product names, IDs, known terms | Misses unknown values |
| Pattern spotter | Regex-style rules | Structured IDs (T-\d+, serial numbers) |
Over-fires on partial matches |
| ML NER | Pre-trained neural model | Generic types (person, org, location) | Domain accuracy varies |
| LLM extraction | Prompt-based, open-ended | Complex or rare patterns | Slow and expensive |
Start with dictionary spotters. They're predictable, fast, and easy to audit.
Add a pattern spotter for structured IDs that aren't in your vocabulary. Reach for ML NER or LLM extraction only if neither covers your needs.