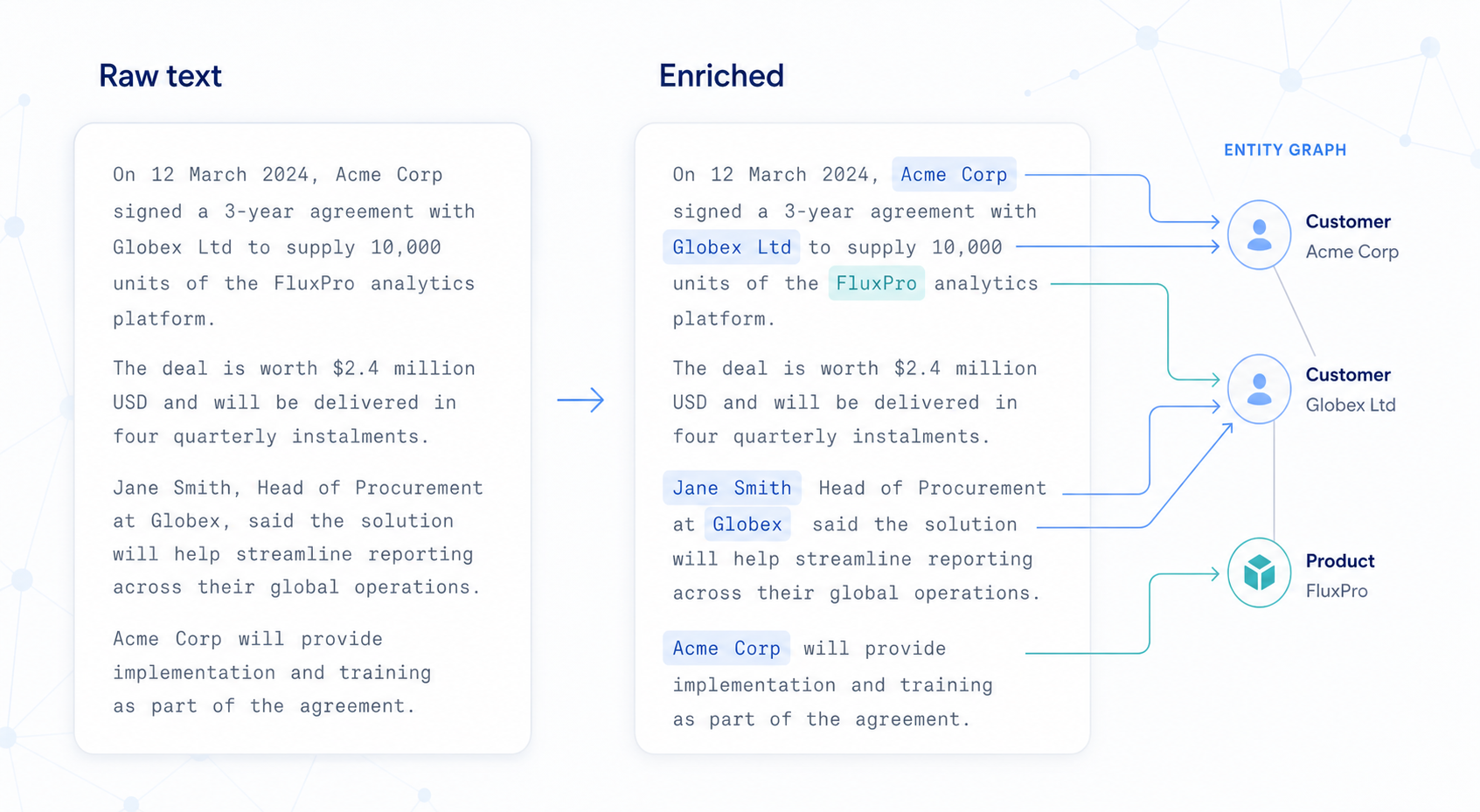
What is NLP enrichment?
After you commit data, Curiosity automatically processes text fields through NLP pipelines. Enrichment turns unstructured text into structured graph data.
Three things enrichment does:
1. Extract — find meaningful spans in free text
"The MBA-2024 battery drains overnight" → entity:
MBA-2024, type:Product
2. Link — connect extracted mentions to existing graph nodes
MBA-2024mention → edge_Mentions→Devicenode with keyMBA-2024
3. Embed — generate dense vectors for semantic search
ticket body → 512-dimensional vector → stored in vector index
The result: your graph grows richer automatically as data flows in. Users can facet by extracted entities. The search engine finds semantically similar content. The AI layer has grounding material to work with.
You configure pipelines once. They apply to every node committed, past and future (after a reparse).