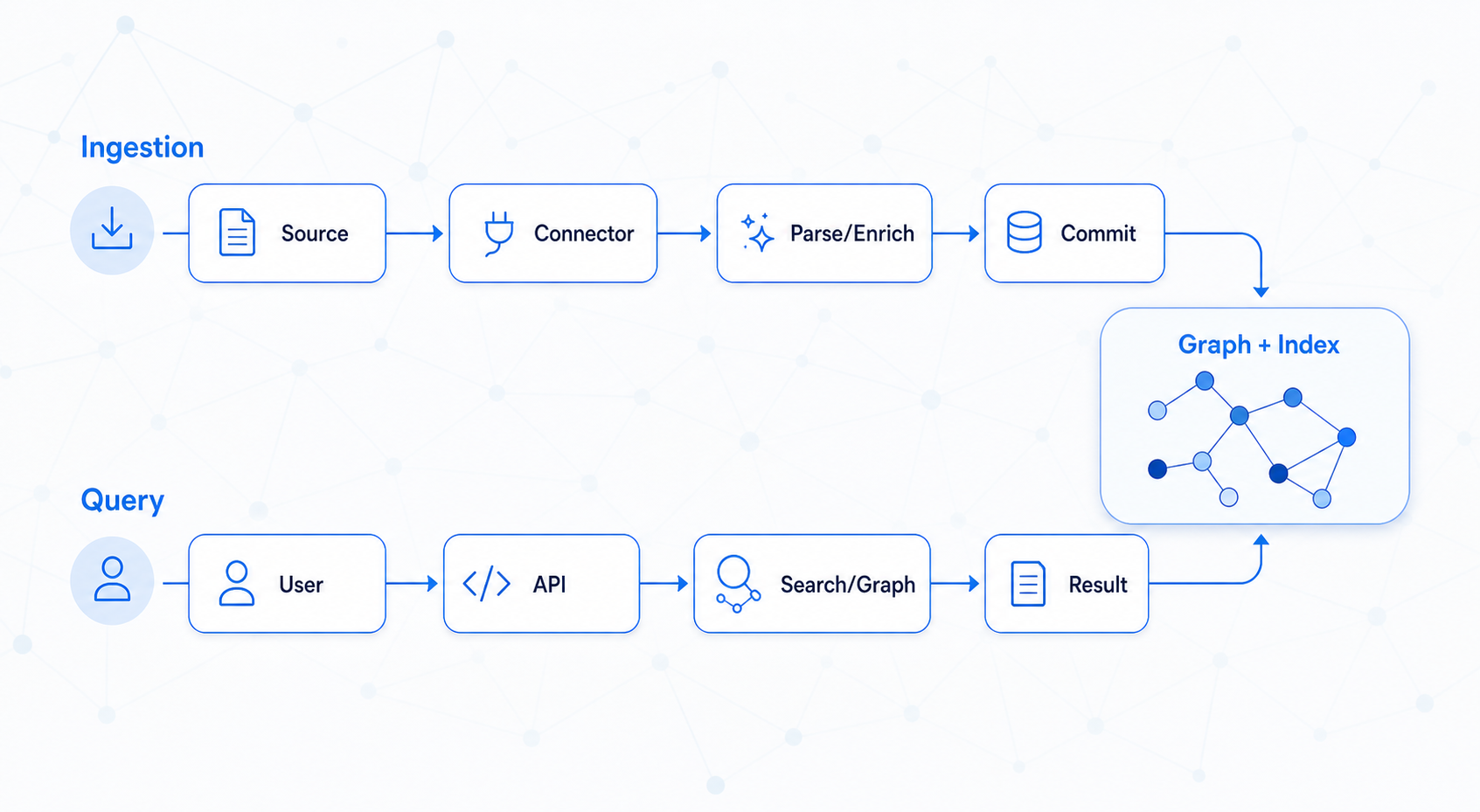
How it fits together
Two flows. One platform.
Ingestion flow (your connector runs this):
Source → Connector → Graph commit
↓
Parsers (text extraction)
↓
NLP pipelines (entities · embeddings)
↓
Search indexes (text + vector)
Query flow (every search or AI call runs this):
User request → Gateway (auth + ReBAC)
↓
Search engine ←→ Graph engine
↓
Ranked results → (optional) LLM → Answer + citations
The two flows are independent. Ingestion is background. Query is synchronous and low-latency. You never trigger the pipeline manually — commit data, wait a few seconds, it's searchable.